|
|

|
|
|
|
|
|

|
|
La lettura
di questa pagina risulterà utile a:
-
gli
utenti Professional che hanno installato un "HTTP Analyze 2.0",
per interpretare i risultati delle statistiche di accesso ai loro
siti web, effettuate dal programma (è disponibile anche il documento
originale in lingua inglese);
-
tutti
gli altri navigatori che desiderano scoprire i segreti della tecnologia
che lavora "dietro le quinte" del mondo di Internet
|
| COS'E' UN SERVER WEB?
Un server web è un programma
installato su un computer che lavora in rete, che attende connessioni
dal mondo esterno per fornire documenti su richiesta dei browser.
Per comunicare, il server
e il browser usano un metodo di comunicazione asincrona chiamato HTTP
(hyper text transaction protocol). Questo protocollo lavora nella
seguente maniera:
1) l'utente accende
il browser e digita un URL
2) il browser si collega all'host cercato e richiede un documento
specifico.
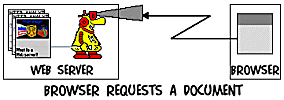
3) Il server web si
occupa di soddisfare la richiesta e spedisce indietro una risposta:

A) se questo documento
esiste, il server web lo invia,
B) se invece esso
non esiste o se l'accesso non è permesso, il server web spedisce
indietro un messaggio di errore.
Il documento
inviato come risposta alla richiesta del browser può contenere oggetti
inclusi. Gli oggetti inclusi sono semplici URL che puntano ad altre
risorse, come un documento, un'immagine, un applet, uno stream video/audio,
o qualsiasi altro oggetto HTML indicabile con un indirizzo.
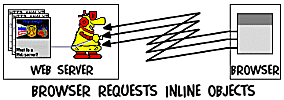 Il browser allora richiede tutti gli oggetti inclusi della corrente
pagina dal server utilizzando i punti 2 e 3 indicati sopra, prima di
mostrare il contenuto di quella pagina.
Il browser allora richiede tutti gli oggetti inclusi della corrente
pagina dal server utilizzando i punti 2 e 3 indicati sopra, prima di
mostrare il contenuto di quella pagina.
Questo metodo di comunicazione è chiamato asincrono, perchè il
browser spedisce molte richieste per i documenti inclusi, senza attendere
una risposta dal server prima di spedire la nuova richiesta), usando
diversi canali di comunicazione.
 Poichè
le richieste del browser sono spesso gestite da differenti processi
del server o da differenti flussi di un processo server, non c'è assolutamente
relazione tra le linee del logfile (il file che tiene traccia degli
eventi) causate dalle risposte dal server a seguito della richiesta
di un documento e dei suoi oggetti inclusi. Poichè
le richieste del browser sono spesso gestite da differenti processi
del server o da differenti flussi di un processo server, non c'è assolutamente
relazione tra le linee del logfile (il file che tiene traccia degli
eventi) causate dalle risposte dal server a seguito della richiesta
di un documento e dei suoi oggetti inclusi.
Per esempio, l'ordine con cui il server registra la trasmissione, avvenuta
con successo, del documento stesso e delle immagini in esso contenute
non è prevedibile e dipende dal tipo di documento, oggetto, dalla velocità
del server, dal sistema operativo, dalla rete e da molti altri parametri.
|
COSA VIENE REGISTRATO?
Ciascuna
risposta del server - che essa indichi successo, un errore o persino
un timeout (cioè nessuna risposta) - viene registrata in un logfile
del server. Le risposte del server si chiamano "Hits". Il numero
totale di hits deve essere uguale al totale numero di linee nel
logfile meno il numero di linee corrotte o vuote. Una tipica linea di
un logfile nel Common Logfile Format appare così:
hostname - - [01/Feb/1998:10:10:00 +0100] "GET /index.html HTTP/1.0" 200 4839
Il campo
hostname contiene il nome di dominio completo (FQDN ovvero Full
Qualified Domain Name) del sito che accede al tuo server (si veda "Casi
Particolari" sotto). I successivi due campi di solito contengono un
meno (`-') per indicare che quei campi sono vuoti. La data
è circondata da parentesi quadrate ('[' e ']'). Il
campo che segue contiene la richiesta. Esso contiene il metodo di richiesta
o request method (GET per esempio), il nome del documento
richiesto (URI), e la specificazione del protocollo (HTTP/1.0).
Il campo successivo contiene il codice di risposta del server (200
sta per un "OK", mentre 404 significherebbe "Documento non
trovato", per esempio). L'ultimo campo contiene la dimensione del documento
(alcuni server registrano il numero di byte trasferiti effettivamente,
mentre altri servers registrano la dimensione del documento, il che
fa differenza se l'utente interrompe il trasferimento prima che il documento
possa essere trasmesso completamente.
Ci sono
altri due formati di logfile; il Combined e l'Extended.
Questi formati aggiungono alla linea del logfile il tipo di browser
o user-agent e il referrer URL (la pagina che contiene
un link al documento richiesto se la richiesta per quel documento è
stata generata seguendo un link) . I formati Combined o Extended
aggiungono i seguenti due campi al Common Logfile Format (CLF)
in una delle due seguenti modalità:
CLF Mozilla/2.0 (X11; IRIX 6.3; IP22) http://foo/bar.html
CLF "http://foo/bar.html" "Mozilla/2.0 (X11; IRIX 6.3; IP22)"
Si noti che nella seconda
form, lo user-agent ed il referrer URL sono circondati
da virgolette, che li rendono ambigui in certi casi come URL errati,
i quali contengono virgolette. Ne consegue che la prima forma dovrebbe
essere preferita.
Le linee mostrate sopra
sono le sole informazioni che il server registra nel logfile. Ci potrebbero
essere molte più informazioni che vengono trasferite dal browser al
server, ma sebbene queste informazioni addizionali siano disponibili
attraverso gli script CGI che vengono eseguiti nel tuo server, esse
non vengono registrate nel logfile. Pertanto, http-analyze può
mostrare solo un riassunto delle informazioni nel logfile - niente di
più, niente di meno.
|
CASI PARTICOLARI
MEMORIZZAZIONE NEL BROWSER:
Dal momento in cui una pagina è stata salvata nella cache del browser,
il browser può inviarci richieste condizionali per documenti o oggetti
inclusi. Questa richiesta condizionale chiede al web server solo di
spedire un documento/oggetto se esso è stato modificato dall'ultima
volta che la pagina è stata richiesta (se la pagina è ancora nella cache
del browser). In questo modo il traffico di rete viene ridotto molto
poichè i documenti devono essere trasferiti solo se sono stati modificati
recentemente. Se una richiesta condizionale arriva, il server risponderà
con un Code 304 (Not Modified) per indicare che il documento
non è stato cambiato o con un Code 200 (OK) se esso è stato
cambiato nel frattempo. Poichè il browser può essere configurato (e
di solito lo è) per spedire solo richieste condizionali una per sessione
e altrimenti incondizionatamente usa la copia dalla chache, tu potrai
non vedere una risposta Code 304 se questi utenti visitano il tuo
sito di nuovo nella stessa sessione. Le richieste condizionali vengono
poi spedite solo se l'utente termina la sessione del browser e più tardi
riaccende il browser.
MEMORIZZAZIONE IN UN SERVER PROXY:
Organizzazioni con un largo numero di utenti - come le grandi aziende,
le università, o i providers - spesso usano un cosiddetto proxy server
principalmente per due motivi:
1) Spesso tali organizzazioni
hanno un firewall per proteggere la loro rete interna da intrusioni.
Questo significa che le loro reti sono logicamente separate dal resto
del mondo, dunque essi devono usare un proxy server perchè esso permette
la comunicazione tra la loro rete locale e l'esterno.
2) Per ridurre il carico
di rete il proxy server agisce come una macchina di copia locale.
Quando una pagina è caricata in un browser attraverso un proxy server,
il proxy salva una copia di questa pagina nella sua cache, come fa
il browser nell'esempio precedentemente descritto. In questo modo,
un documento che viene richiesto molto spesso dagli utenti della stessa
rete locale, ha bisogno di essere trasferito al proxy solo una volta,
che poi risponderà alle future richieste delle stessa pagina dalla
sua cache locale invece che connettersi al server web da cui il documento
è originariamente stato tratto.
Entrambe
le forme di memorizzazione rendono tecnicamente impossibile tenere il
conto dei visitatori o tracciare le loro venute nel tuo sito web. Tutto
quello che vedi nel logfile del tuo server sono solo pochi iniziali
Hit dal proxy o dal browser e probabilmente alcuni Code 304
risultanti da richieste condizionali spedite dal proxy o dal browser,
dipendenti dalle configurazioni prescelte per il proxy ed il browser.
|
DEFINIZIONE DEI TERMINI
Il rapporto della statistica
contiene, insieme ad altre, le seguenti informazioni:
il numero di Hit,
304, file, pageview, sessioni, dati spediti (in KB)
l'ammontare dei dati
richiesti, trasferiti, e salvati dalla cache (in KB)
il numero di URL,
siti, e sessioni per mese
il numero di tutti
i codici di risposta diversi da 200 (OK)
la media di Hit per
giorno della settimana e nell'ultima settimana
la media più alta
di Hit in un giorno ed in un'ora
il numero di Hit,
file, 304, siti, dati spediti ogni giorno
gli ultimi 5 giorni,
24 ore, 5 minuti e 5 secondi del periodo di osservazione
gli ultimi 30 tra
gli URL più comunemente visitati (Hit, 304, dati spediti)
i dieci URL meno frequentemente
visitati (Hit, 304, dati spediti)
gli ultimi 30 domini
client che hanno visitato il tuo server più spesso
gli ultimi 30 tipi
di browser
gli ultimi 30 host
cui si è fatto riferimento
la lista dettagliata
e sintetica di tutti i file richiesti
la lista dettagliata
e sintetica di tutti i siti per dominio (numerico e letterale)
la lista dettagliata
e sintetica di tutti i tipi di browser
la lista dettagliata
e sintetica di tutti gli URL cui si è fatto riferimento
La seguente tabella riassume
il significato di tutti i termini nella relazione di statistica che
non si spiegano da soli:
| TERMINE |
COLORE |
SIGNIFICATO |
| Hit |
 |
Hit
è qualsiasi risposta del server a seguito di una richiesta del
browser. Questo include qualsiasi risposta del server, non solo
file di testo o documenti. Se per esempio una pagina HTML comprende
due immagini, il server genera tre Hit quando la pagina viene
richiamata, uno per la pagina HTML stessa e due per le due immagini
incluse.
|
| File |
 |
Se
l'utente richiede un documento, la richiesta è corretta e il server
resituisce un file, questo è contato come una risposta Code
200 (OK). Di nuovo, "file" qui significa qualsiasi
tipo di file.
|
| Code
304 |
 |
Una
risposta Code 304 (Not Modified) è generato dal server
se il documento non è stato aggiornato dall'ultima volta che è
stato richiesto dall'utente e perciò non c'è bisogno effettivamente
di rispedirlo. Questo accade quando il browser (o il server proxy
tra il browser e il tuo server web) ha ancora una copia aggiornata
della pagina nella sua cache e può mostrare la pagina senza richiederne
l'attuale contenuto. Questa tecnica è usata per ridurre il traffico
di rete, ma essa genera dei risultati nelle relazioni di statistica
riguardo al numero di visitatori non veritieri. Comunque, la percentuale
tra file e codici 304 riflette l'efficenza generale
del meccanismo di memorizzazione, almeno per quegli Hit che hanno
raggiunto il server.
|
| Pageview |
 |
Pageview
sono tutti quei file che o hanno un suffisso di file di testo
(.html, .text) o che sono file di indice di cartella.
Questo numero permette di stimare il numero di "reali"
documenti trasmessi dal tuo server. Se definito correttamente
, l'analizzatore classifica file di testo (documenti) come pageviews.
Queste pageview non includono immagini, CGI scripts, Applet Java
o qualsiasi altro oggetto HTML tranne tutti i file che terminano
con uno dei suffissi predefiniti per pageview, come .html
o .text.
|
| Altre
risposte |
 ¹ ¹ |
Ci
sono molte altre risposte oltre aCode 200 (OK) e Code
304 (Not Modified), specialmente nello standard, il protocollo
HTTP 1.1. Per esempio, il server può generare una risposta Code
302 (Redirezionato) se una pagina è stata spostata, un Code
401 (Richiesta non autorizzata) se l'accesso al documento
è vietato o un Code 404 (Non trovato) se la pagina richiesta
non esiste su quel server. Si vedano le
specifiche HTML per informazioni circa tutte le risposte valide
da un server web. Si noti che l'http-analyze non riconosce
le risposte dell'HTTP/1.1 in accordo con l'RFC2068.
|
| KByte
trasferiti |
 |
Questo
è l'ammontare dei dati spedito durante l'intero periodo di osservazione
come riportato dal server. Si noti che alcuni server registrano
la dimensione di un documento invece che il numero effettivo dei
byte trasferiti. Mentre in molti casi questo è lo stesso, se un
utente interrompe la trasmissione premendo il pulsante "Termina"
del browser prima che la pagina sia stata ricevuta completamente,
alcuni server (per esempio tutti i Netscape web server) non registrano
l'ammontare dei dati trasferiti ma l'ammontare dei dati che sarebbero
stati trasferiti se l'utente avesse caricato completamente la
pagina.
|
| KByte
richiesti |
¹ |
Questo
è l'ammontare di dati durante l'intero periodo di osservazione.
http-analyze ricava questo numero sommando i valori dei
KByte trasferiti e dei KByte salvati mediante la cache
(si veda sotto).
|
| KByte
salvati mediante la cache |
¹ |
L'ammontare
dei dati salvati con svariati metodi di caching come in un proxy
server o in un browser. Questo valore si ricava moltiplicando
il numero diCode 304 (Not Modified) per file con la dimensione
del corrispondente file. Nota: considerato che http-analyze
può determinare la dimensione di un file solo se esso è stato
richiesto almeno una volta nello stesso periodo di osservazione,
il valore per KBytes salvati mediante la cache e KBytes
richiesti sono proprio approssimazioni dei valori reali.
|
| Unique URLs |
|
Unique
URLs sono il numero di tutti i singoli, validi URL richiesti
in un dato periodo di osservazione. Questo mostra il numero di
tutti i diversi file richiesti almeno una volta nel corrispondente
periodo di osservazione.
|
| Unique
sites |
|
Questa
è la somma di tutti i singoli host che accedono al server durante
un dato intervallo di tempo. L'intervallo di tempo è strettamente
collegato alla lunghezza del mese corrente. Questo significa che
se un host accede al tuo server molto spesso, esso viene contato
solo una volta durante l'intero mese.
|
| Sessions |
|
Simile
a unique sites, questo è il numero di unique hosts
che accedono al server durante una dati intervallo di tempo. Questo
intervallo di tempo è generalmnte pari ad un giorno, ma può essere
cambiato con l'opzione -u o le direttive riguardo a Session
nel file di configurazione. Per esempio, se la finestra di tempo
è di due ore, tutti gli accessi da un certo host in meno di due
dopo il primo accesso vengono riuniti insieme in una sessione.
Tutti gli accessi seguenti a più di due ore dal primo saranno
contati come una nuova sessione. In questo modo tu puoi fare una
stima di quante sessioni vengono aperte su un differente sito
per accedere al tuo server.
|
|
¹ indicato solo
nella pagina riassuntiva.
|
|
|